Where Do We Come From? What Are We? Where Are We Going?
Let’s stop for a moment and consider where we are. As a total boomer, I sincerely doubt that 10 or so years ago anyone could have predicted that web development would go this far.
Utility desktop applications are a thing of the past because everything can be done in a browser. In fact, applications that need to use lower-level APIs that aren’t available in the browser are also written using browser engines and languages because it’s makes them easier to maintain.
Mobile applications can be easily replaced by tools used for web development – see React Native, NativeScript. In addition, we have PWA, which easily “imitates” the operation of mobile applications. Additionally, components that power an application written in Vue or React can easily share various code elements between platforms.
We have to admit one thing – web applications are currently a powerhouse which will be difficult to bring down to the ground floor. As a user, I see myself using them practically everywhere: communicating via Slack, using a code editor, making presentations or even writing a blog article.
It’s hard to predict what will happen in a few years. WebAssembly is coming into play, and it will allow us to move applications that require more complex calculations into the browser world. One fact, however, remains unchanged – it is really hard to find an obstacle to build with the use of web technologies such an application that we can only dream of.
The big bang in internet reality
To the point – let’s go back to the past for a moment, before the first more significant web frameworks appeared and applications were developed in an imperative way. Each interactive mechanic on a page was handled manually and was responsible for a specific action.
The best example that can be cited is the jQuery library – at the time one of the most popular solutions for handling simple events. With its help, various drop-down menus, transitions, animations, calculators and similar mechanics were implemented.
It’s worth mentioning that problems in more complex applications were noticed already then – in places where different, independent parts had to, e.g., react to a proper click or typing something. Most applications did not have an explicit state, and were instead rescued by, for example, the attributes of elements or the classes they had.
At the time, it was clear that the current approach lacked reactivity – a structured way for components to communicate with each other and share, e.g., their state or different events, which made applications easier to maintain and allowed them to give a good user experience at a low cost.
First Steps Towards Well-Known Frameworks
Over time, the first front-end frameworks began to appear on the horizon, aiming at structuring the architecture for more complex applications.
These frameworks were mainly based on the MVC pattern – some suggested a more manual approach, such as Backbone.js, while others, such as Knockout.js, hooked into two-way data binding.
Still, one could feel that writing the application was more difficult, required much more coding and did not necessarily produce the results that were intended or compensated for the time lost in application development.
The main reason why finding the golden mean in the JS ecosystem was hard was that it was a bit of an oddity among well-known programming languages that have long had their paths paved.
And I don’t want to dwell here on exactly what paths accompanied the development of various frameworks throughout history. However, it is important to note one thing – the maturation time of the JS ecosystem in the browsers was not easy and faced many trials.
This is the only reason why today we can build web applications and develop them in a very easy and painless way.
Basic Information and Slight Comparison
Instead of throwing meat, as is customary on the Internet, let’s take a look at both libraries, gather information about them and compare them – both in theory and in practice.
NOTE: The description of mechanisms working in Vue refers specifically to version 2. Version 3 introduces a lot of significant changes, but is not a real competitor to React at the moment, if only due to its maturity – Vue 3 release date: September 18, 2020.
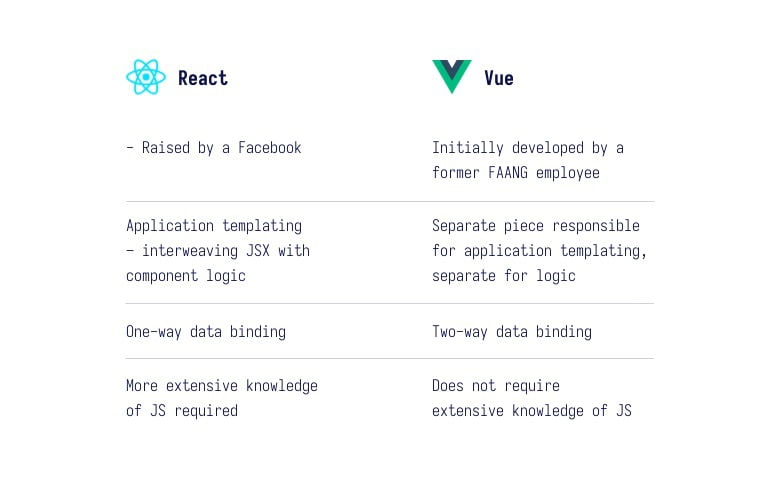
Let’s get one thing straight – when digging deeper into both libraries, you can see that actually there are more similarities than differences. Leaving aside the manner of using the libraries as such – both of them have very similar concepts of how they work. Both are powered by a similar ecosystem and their use is not diametrically different.
● The devil is in the details – the more often we use a tool, the bigger disadvantages of its different solutions we notice. A good example here can be two-way data binding, which is most often used in Vue as a v-model property: it often makes things easier, takes care of a lot of things automatically and does not require coding in additional support for changing values.
However, there are cases when we need to specifically track a change attempt and react accordingly, in which case of the v-model-based components often forces us to mess around with other Vue mechanics such as computed property, making the achieved effect often look much worse than with a manual approach;
● Another interesting aspect is JSX, which is such a “vagrant” way to template rendered content using React. It has different opinions in the developer community.
From my observations, it seems that developers using environment other than JS, e.g. PHP or C#, are more inclined to template views in a way that Vue does.
To sum up – templates known from Vue allow to define views in a very clear and elegant way, while React’s JSX allows to build them in many cases faster, tailored to specific needs and often requires less code to build diverse structures;
● Let us also look at the ecosystems of these two tools. In principle, we can say that they do not differ in anything. Both of them are called libraries for a reason – they provide the bare minimum for reactive web application support.
Whereas the rest, related to communication with API, data flow, UI components used around different subpages, are the so-called vendors – libraries taken from outside, which need to be properly attached to the project. It is a bit like the world of Lego: if you want to build a coherent whole – you have to put it together from individual, small blocks.
This allegory refers to precisely attached components, which are the power of applications created with React or Vue;
● An important thing, especially for people who are not that experienced in the JS environment, is the level of entry into a particular library. In other words – the complexity of the tool, consisting of the direct time you need to spend on understanding its mechanics.
I think one thing has to be unequivocally stated here – in the case of Vue, it is much simpler. We have two-way data binding, we have an elegantly specified template that is deceptively similar to solutions in other languages, e.g. twig, and finally – we have no headaches caused by learning about theories regarding the operation of individual hooks and cases in which specific mechanics must be used.
What Do the Statistics Say?
Going directly with the voice of the crowd is not exactly a good choice. However, a good step towards making a good decision is to analyze what people who have interacted with these libraries are saying.
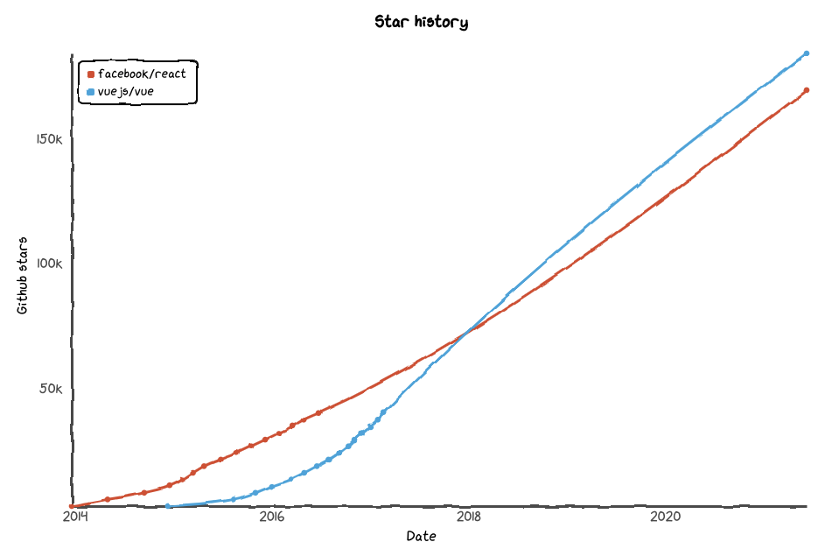
And yes – stars on github can be an indicator of how much the community of a particular library is involved in its development, how it is perceived by developers and whether they are interested in where it is going. Engineers who star a particular repository often get notifications on new releases or code changes, translating into their direct knowledge of the library.
However, the number of stars on github shouldn’t be seen as an oracle – not every developer who likes a tool will leave a mark – instead, I would take it as a sign of pure passion that developers have for a particular open-source project.
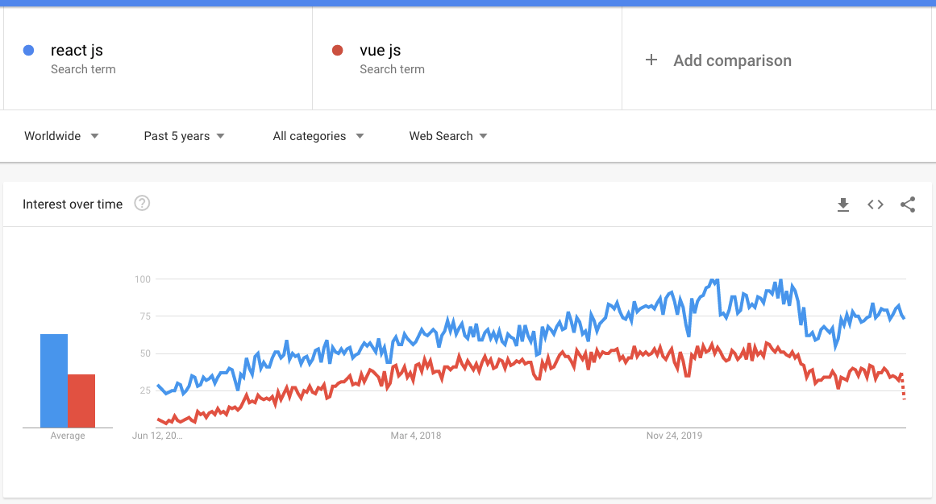
Google Trends is a well-known service that allows us to study the interest in specific topics over time. Although it is not a rational indicator of quality or use, it can provide all kinds of analyses.
It is easy to see that the course of the last 5 years has been outlined fairly similarly when it comes to comparing the two protagonists of the today’s article. The basic conclusion that can be drawn from the chart is that React is higher when it comes to search popularity in relation to its opponent.
To be clear – being on top in Google Trends does not mean that a library is better. It’s about crowd popularity, as I mentioned before – probably more people have heard about this tool, it may have aroused more interest among CTOs, software developers or people who just want to learn a particular tool.
Is this graph reflected in reality? Somewhat, yes. Generally speaking – among the people surveyed, more of them show diversely sophisticated knowledge of React than Vue. What opinions can you get is talking with these people? I will try to outline this in the next paragraph.

State of JS is a site that surveys people working in JavaScript-related technologies every year. Its goal is to gather information from developers about how they view the tools they work with on a daily basis.
The questions cover individual tools for different purposes – e.g. tools used on the front-end and on the back-end, but also tools for testing, application state management, etc. Each of these questions is not a simple yes/no answer, the site asks a series of questions about the tool itself, interests, experiences and an overall evaluation that boils down to the sentence “Would you use this tool in future projects?”
The site itself allows you to do a lot of analyses, compare relevant tools and sometimes find out about lesser known libraries that are starting to do well in the JS world, gathering popularity while enjoying a high “happiness to use” rate. I sincerely encourage you to browse the content on this site.
Let’s summarize the section with statistics. Analyzing different types of graphs can often be a very good option for comparing different aspects of given topics. However, it is important to take into account that following the voice of the crowd will not necessarily be the smartest thing to do. Instead, you can make an informed decision using some of the lessons learned from chart analyses.
Best Pick for Developer
Earlier, I mentioned the lower threshold of entry to Vue – indeed, it allows you to focus a little faster on the actual development of the application, using the tool and reducing to a minimum the time needed to get acquainted with the environment, mechanics, and various use-cases.
In general, my opinion is that Vue is more suitable for people who have not yet dealt with front-end libraries. Certainly, it will allow you in a more encouraging way to get satisfactory results in a short time.
However, let’s say it loudly – the lack of knowledge of the language in which we use specific tools will hurt us sooner or later. It is a negligible element for simple things, but as the complexity of the created applications increases, it will be more and more difficult to build applications in a decent way without good knowledge of JavaScript.
I don’t really refer to being able to write some sophisticated functions, because this part can be largely replaced by, e.g., vendors. I’m referring to some common mistakes that can be made in the language and not being aware that the incorrect behavior is not due to the use of the library, but to the use of the language. The most common mistake that manifests itself here is the so-called immutability – that is, the knowledge of the reference mechanism in JavaScript.
I’m not able to suggest which library is better for developers more or less familiar with JavaScript. But I know one thing – if you want to have a real idea of how development with both tools looks like “from the inside” – try to write applications in each of them. This will give you an idea, allow you to see which mechanisms appeal to you more and what is a better choice for you.
As I mentioned earlier – both libraries are powered by similar ecosystems, have similar views on building applications with small components. Both libraries are doing well – there is no indication that either of them will go away in the near future. Consequently, job offers in both of them will remain at a similar level.
The conclusions are simple – use what suits you; gather experience and evaluate. This will help you develop a rational approach to whether it is better to use one or the other library in a particular project; also, try to experiment – nothing teaches as profoundly as the mistakes made in the past.
Best Pick for CTO
It is not a secret that there is no golden mean that will be the best solution for a particular project. Especially on the front-end, the tools used to build applications get old quickly and it is often hard to find your feet in the latest trends.
However, the choice of technology is not, or at least should not be, a toss-up on what fits in with current trends. Instead, we should direct it towards specific expectations and assumptions about the application we are going to build. Each of the compared libraries has its strengths and weaknesses, which matched to the use-case will allow us to make the most reasonable choice.
An interesting option may turn out to be technology summaries of large corporations, which often describe their use-cases, how the development of huge applications was or is going and what mistakes they made in the past. Perhaps we will find among them cases that are particularly interesting in the context of choosing a library for a particular project.
The features that we should consider in order to choose the right tools for the application being built are: the time of application development, the ease of application maintenance, the complexity of the application and the experience of developers in using specific libraries.
Developers are the people who spend the most time in the tools I compare and they are the ones who can provide the best advice and help you make the best choice in the great clash of libraries. It is during application development that you see the various problems that arise directly from the choice of technology, and have the best view of what things undermine the use of a particular tool for particular features.
As I mentioned earlier – both libraries don’t seem to be disappearing from the market, at least not in the next few years. Instead of making decisions based on statistics and opinions
of various people from the internet – maybe a better option is to simply talk to the developers.
Present to them what is expect from the application, what time we have for its delivery and allow for a loose exchange of opinions on what they think about both solutions before we make the final decision.
Conclusions
Internet wars usually – or perhaps in every case – are pointless. There will always be people who will stubbornly claim that their choice is better without giving any rational arguments confirming their decision.
Instead of being blinded by specific choices – let’s focus on analysis, try to draw appropriate conclusions and use them to adjust or reject a specific solution.
Just as the title implies – I do not intend to crown any particular library as a cure for every pain. Instead, a few hypotheses are presented and the strong and weak points of both libraries are revealed. I have given some advice on what to look for when choosing between them in order to make a wise decision and not be guided by trends or random people from the internet.
Each tool can suit the needs of the project well enough. Neither of them will disappear from the market quickly in the coming years. Both have powerful communities and quite a bit of maturity, which shows us that these two are doing quite well.
The final choice lies in your hands. However, if you have any doubts or just want to discuss your case with The Codest – feel free to contact us!
Read more:
Why you should (probably) use Typescript