¿De dónde venimos? ¿Qué somos? ¿Hacia dónde vamos?
Detengámonos un momento y consideremos dónde estamos. Como boomer total, dudo sinceramente que hace unos 10 años alguien hubiera podido predecir que desarrollo web llegaría tan lejos.
Las aplicaciones utilitarias de escritorio son cosa del pasado porque todo puede hacerse en un navegador. De hecho, las aplicaciones que necesitan utilizar APIs de bajo nivel que no están disponibles en el navegador también se escriben utilizando motores y lenguajes de navegador porque así es más fácil mantenerlas.
Las aplicaciones móviles pueden sustituirse fácilmente por herramientas utilizadas para web desarrollo - véase React NativoNativeScript. Además, tenemos PWA, que "imita" fácilmente el funcionamiento de las aplicaciones móviles. Además, los componentes que alimentan una aplicación escrita en Vue o React puede compartir fácilmente varios código elementos entre plataformas.
Tenemos que admitir una cosa: las aplicaciones web son actualmente una potencia que será difícil bajar a la planta baja. Como usuario, me veo utilizándolas prácticamente en todas partes: comunicándome a través de Slack, utilizando un editor de código, haciendo presentaciones o incluso escribiendo un artículo en un blog.
Es difícil predecir lo que ocurrirá dentro de unos años. WebAssembly está entrando en juego, y permitirá us para trasladar las aplicaciones que requieren cálculos más complejos al mundo de los navegadores. Un hecho, sin embargo, se mantiene sin cambios - es realmente difícil encontrar un obstáculo para construir con el uso de tecnologías web tal aplicación que sólo podemos soñar.
El big bang en la realidad de Internet
Al grano: volvamos al pasado por un momento, antes de que aparecieran los primeros frameworks web más significativos y las aplicaciones se desarrollaran de forma imperativa. Cada mecánica interactiva de una página se manejaba manualmente y era responsable de una acción específica.
El mejor ejemplo que se puede citar es la biblioteca jQuery, en su momento una de las soluciones más populares para gestionar eventos sencillos. Con su ayuda se implementaron varios menús desplegables, transiciones, animaciones, calculadoras y mecánicas similares.
Merece la pena mencionar que ya entonces se detectaron problemas en aplicaciones más complejas, en lugares en los que distintas partes independientes debían, por ejemplo, reaccionar a un clic adecuado o a teclear algo. La mayoría de las aplicaciones no tenían un estado explícito, y en su lugar eran rescatadas, por ejemplo, por los atributos de los elementos o las clases que tenían.
En aquel momento, estaba claro que el enfoque actual carecía de reactividad: una forma estructurada de que los componentes se comunicaran entre sí y compartieran, por ejemplo, su estado o distintos eventos, lo que facilitaba el mantenimiento de las aplicaciones y les permitía ofrecer una buena experiencia de usuario a bajo coste.
Primeros pasos hacia marcos bien conocidos
Con el tiempo, empezaron a aparecer en el horizonte los primeros frameworks front-end, destinados a estructurar la arquitectura de aplicaciones más complejas.
Estos frameworks se basaban principalmente en el patrón MVC - algunos sugerían un enfoque más manual, como Backbone.js, mientras que otros, como Knockout.js, se enganchaban en dos vías datos encuadernación.
Aun así, se podía pensar que escribir la aplicación era más difícil, requería mucha más codificación y no producía necesariamente los resultados previstos ni compensaba el tiempo perdido en el desarrollo de la aplicación.
La razón principal por la que encontrar la media áurea en el JS ecosistema era difícil era que era un poco una rareza entre conocidos lenguajes de programación que hace tiempo que tienen el camino allanado.
Y no quiero detenerme aquí en cuáles han sido exactamente los caminos que han acompañado el desarrollo de los distintos frameworks a lo largo de la historia. Sin embargo, es importante señalar una cosa - el tiempo de maduración del ecosistema JS en los navegadores no fue fácil y se enfrentó a muchas pruebas.
Esta es la única razón por la que hoy en día podemos construir aplicaciones web y desarrollarlas de una manera muy fácil y sin dolor.
Información básica y ligera comparación
En lugar de echar carne en el asador, como es habitual en Internet, echemos un vistazo a ambas bibliotecas, recabemos información sobre ellas y comparémoslas, tanto en la teoría como en la práctica.
NOTA: La descripción de los mecanismos que funcionan en Vue se refiere específicamente a la versión 2. La versión 3 introduce muchos cambios significativos, pero no es un competidor real de React por el momento, aunque sólo sea por su madurez - Vue 3 fecha de lanzamiento: 18 de septiembre de 2020.
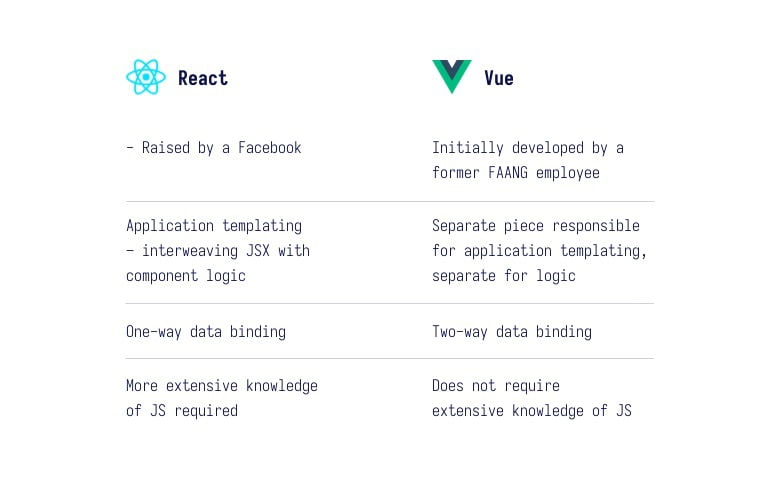
Dejemos una cosa clara: al profundizar en ambas bibliotecas, se puede ver que en realidad hay más similitudes que diferencias. Dejando a un lado la forma de utilizar las bibliotecas como tal - ambas tienen conceptos muy similares de cómo funcionan. Ambas están impulsadas por un ecosistema similar y su uso no es diametralmente diferente.
● El diablo está en los detalles: cuanto más a menudo usamos una herramienta, mayores desventajas de sus diferentes soluciones notamos. Un buen ejemplo de ello puede ser la vinculación bidireccional de datos, que se utiliza con mayor frecuencia en Vue como una propiedad v-model: a menudo facilita las cosas, se encarga de muchas cosas automáticamente y no requiere codificar soporte adicional para cambiar valores.
Sin embargo, hay casos en los que necesitamos hacer un seguimiento específico de un intento de cambio y reaccionar en consecuencia, en cuyo caso los componentes basados en v-model nos obligan a menudo a trastear con otros Vue mecánica como la propiedad computada, haciendo que el efecto conseguido a menudo parezca mucho peor que con un enfoque manual;
● Otro aspecto interesante es JSX, que es una forma tan "vaga" de plantillas de contenido renderizado utilizando React. Tiene diferentes opiniones en la comunidad de desarrolladores.
Según mis observaciones, parece que los desarrolladores que utilizan un entorno distinto de JS, por ejemplo PHP o C#, se inclinan más por las vistas de plantilla de forma que Vue lo hace.
En resumen - plantillas conocidas de Vue permiten definir vistas de una forma muy clara y elegante, mientras que JSX de React permite construirlas en muchos casos más rápido, adaptadas a necesidades específicas y a menudo requiere menos código para construir diversas estructuras;
● Veamos también los ecosistemas de estas dos herramientas. En principio, podemos decir que no difieren en nada. Ambas se llaman bibliotecas por una razón: proporcionan lo mínimo para el soporte de aplicaciones web reactivas.
Mientras que el resto, relacionado con la comunicación con API, El flujo de datos, los componentes de la interfaz de usuario utilizados en las distintas subpáginas son los denominados proveedores, es decir, bibliotecas externas que deben conectarse correctamente a la aplicación. proyecto. Es un poco como el mundo de Lego: si quieres construir un todo coherente, tienes que unirlo a partir de pequeños bloques individuales.
Esta alegoría se refiere precisamente a los componentes adjuntos, que son la fuerza de las aplicaciones creadas con React o Vue;
● Una cosa importante, especialmente para las personas que no tienen tanta experiencia en el entorno JS, es el nivel de entrada en una biblioteca en particular. En otras palabras - la complejidad de la herramienta, que consiste en el tiempo directo que necesita para pasar en la comprensión de su mecánica.
Creo que hay una cosa que hay que afirmar inequívocamente: en el caso de Vuees mucho más simple. Tenemos enlace de datos bidireccional, tenemos una plantilla elegantemente especificada que es engañosamente similar a las soluciones en otros lenguajes, por ejemplo twig, y finalmente - no tenemos dolores de cabeza causados por el aprendizaje de teorías sobre el funcionamiento de los ganchos individuales y los casos en los que se deben utilizar mecánicas específicas.
¿Qué dicen las estadísticas?
Dejarse llevar directamente por la voz de la multitud no es precisamente una buena elección. Sin embargo, un buen paso para tomar una buena decisión es analizar lo que dicen las personas que han interactuado con estas bibliotecas.
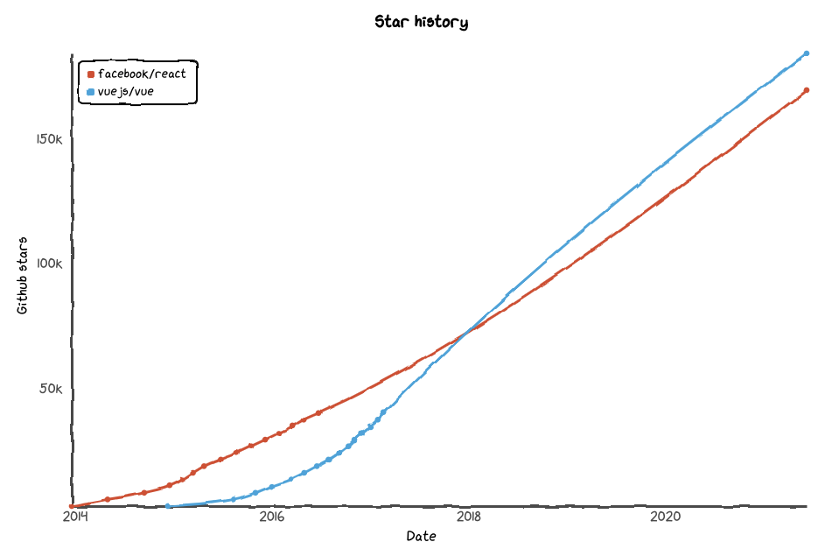
Y sí... estrellas en github puede ser un indicador de hasta qué punto la comunidad de una biblioteca concreta participa en su desarrollo, cómo la perciben los desarrolladores y si les interesa hacia dónde se dirige. Ingenieros que protagonizan un repositorio concreto suelen recibir notificaciones sobre nuevas versiones o cambios en el código, lo que se traduce en su conocimiento directo de la biblioteca.
Sin embargo, el número de estrellas en github no debe verse como un oráculo -no todos los desarrolladores a los que les gusta una herramienta dejarán una marca-, sino que yo lo tomaría como un signo de la pura pasión que los desarrolladores sienten por un proyecto de código abierto concreto.
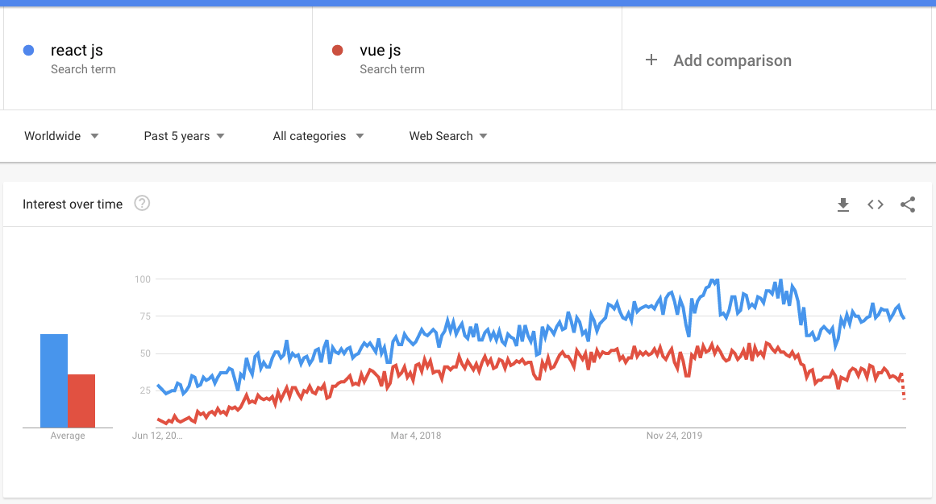
Tendencias de Google es un conocido servicio que permite estudiar el interés por determinados temas a lo largo del tiempo. Aunque no es un indicador racional de calidad o uso, puede proporcionar todo tipo de análisis.
Es fácil ver que el transcurso de los últimos 5 años se ha perfilado de forma bastante similar cuando se trata de comparar a los dos protagonistas del artículo de hoy. La conclusión básica que puede extraerse del gráfico es que React es superior en popularidad de búsqueda en relación con su oponente.
Para que quede claro: estar en los primeros puestos de Google Trends no significa que una biblioteca sea mejor. Se trata de la popularidad de la multitud, como he mencionado antes - probablemente más personas han oído hablar de esta herramienta, puede haber despertado más interés entre CTOs, desarrolladores de software o personas que sólo quieren aprender una herramienta concreta.
¿Se refleja este gráfico en la realidad? En cierto modo, sí. En general, entre las personas encuestadas, son más las que muestran un conocimiento diverso y sofisticado de React que Vue. ¿Qué opiniones puedes obtener hablando con estas personas? Intentaré esbozarlo en el siguiente párrafo.

Estado de JS es un sitio web que encuesta anualmente a personas que trabajan en tecnologías relacionadas con JavaScript. Su objetivo es recabar información de los desarrolladores sobre cómo ven las herramientas con las que trabajan a diario.
Las preguntas abarcan herramientas individuales para distintos fines: por ejemplo, herramientas utilizadas en el front-end y en el back-end, pero también herramientas para pruebas, gestión del estado de la aplicación, etc. Cada una de estas preguntas no es una simple respuesta de sí/no, el sitio hace una serie de preguntas sobre la herramienta en sí, intereses, experiencias y una evaluación general que se reduce a la frase "¿Utilizaría esta herramienta en futuros proyectos?"
El sitio en sí te permite hacer un montón de análisis, comparar herramientas relevantes y, a veces, descubrir librerías menos conocidas a las que les está empezando a ir bien en el mundo del JS, ganando popularidad a la vez que disfrutan de un alto índice de "felicidad de uso". Le animo sinceramente a navegar por el contenido de este sitio.
Resumamos la sección con estadísticas. Analizar distintos tipos de gráficos puede ser a menudo una muy buena opción para comparar diferentes aspectos de determinados temas. Sin embargo, es importante tener en cuenta que seguir la voz de la multitud no será necesariamente lo más inteligente. En su lugar, puede tomar una decisión informada utilizando algunas de las lecciones aprendidas de los análisis de gráficos.
La mejor opción para desarrolladores
Antes he mencionado el umbral más bajo de entrada a Vue - De hecho, permite centrarse un poco más rápido en el desarrollo real de la aplicación, utilizando la herramienta y reduciendo al mínimo el tiempo necesario para familiarizarse con el entorno, la mecánica y los distintos casos de uso.
En general, mi opinión es que Vue es más adecuado para las personas que aún no se han ocupado de las bibliotecas front-end. Sin duda, le permitirá de una forma más alentadora obtener resultados satisfactorios en poco tiempo.
Sin embargo, digámoslo en voz alta: la falta de conocimiento del lenguaje en el que utilizamos herramientas específicas nos perjudicará tarde o temprano. Es un elemento insignificante para las cosas sencillas, pero a medida que aumente la complejidad de las aplicaciones creadas, será cada vez más difícil construir aplicaciones de forma decente sin un buen conocimiento de JavaScript.
Realmente no me refiero a ser capaz de escribir algunas funciones sofisticadas, porque esta parte puede ser sustituida en gran medida por, por ejemplo, vendedores. Me refiero a algunos errores comunes que se pueden cometer en el lenguaje y no ser conscientes de que el comportamiento incorrecto no se debe al uso de la librería, sino al uso del lenguaje. El error más común que se manifiesta aquí es la llamada inmutabilidad - es decir, el conocimiento del mecanismo de referencia en JavaScript.
No puedo sugerir qué librería es mejor para los desarrolladores más o menos familiarizados con JavaScript. Pero sé una cosa - si quieres tener una idea real de cómo es el desarrollo con ambas herramientas "desde dentro" - intenta escribir aplicaciones en cada una de ellas. Esto te dará una idea, te permitirá ver qué mecanismos te atraen más y cuál es una mejor opción para ti.
Como he mencionado antes, ambas bibliotecas se nutren de ecosistemas similares y tienen puntos de vista parecidos sobre la creación de aplicaciones con componentes pequeños. Ambas bibliotecas funcionan bien y no hay indicios de que vayan a desaparecer en un futuro próximo. En consecuencia, las ofertas de empleo en ambas se mantendrán a un nivel similar.
Las conclusiones son sencillas: utiliza lo que te convenga; acumula experiencia y evalúa. Esto le ayudará a desarrollar un enfoque racional sobre si es mejor utilizar una u otra biblioteca en un proyecto concreto; además, intente experimentar: nada enseña tan profundamente como los errores cometidos en el pasado.
La mejor elección para CTO
No es un secreto que no existe una media de oro que sea la mejor solución para un proyecto concreto. Especialmente en el front-end, las herramientas utilizadas para construir aplicaciones envejecen rápidamente y a menudo es difícil encontrar los pies en las últimas tendencias.
Sin embargo, la elección de la tecnología no es, o al menos no debería ser, un cara o cruz sobre lo que encaja con las tendencias actuales. Por el contrario, deberíamos orientarla hacia expectativas y supuestos concretos sobre la aplicación que vamos a construir. Cada una de las bibliotecas comparadas tiene sus puntos fuertes y débiles, que ajustados al caso de uso nos permitirán hacer la elección más razonable.
Una opción interesante pueden ser los resúmenes tecnológicos de las grandes empresas, que suelen describir sus casos de uso, cómo iba o va el desarrollo de grandes aplicaciones y qué errores cometieron en el pasado. Tal vez encontremos entre ellos casos especialmente interesantes en el contexto de la elección de una biblioteca para un proyecto concreto.
Las características que debemos tener en cuenta para elegir las herramientas adecuadas para la aplicación que se está construyendo son: el tiempo de desarrollo de la aplicación, la facilidad de mantenimiento de aplicacionesla complejidad de la aplicación y la experiencia de los desarrolladores en el uso de bibliotecas específicas.
Los desarrolladores son las personas que pasan más tiempo en las herramientas que comparo y son los que pueden ofrecerte los mejores consejos y ayudarte a hacer la mejor elección en el gran choque de bibliotecas. Es durante el desarrollo de la aplicación cuando se ven los diversos problemas que surgen directamente de la elección de la tecnología, y tienen la mejor visión de qué cosas minan el uso de una herramienta concreta para unas funciones determinadas.
Como he mencionado antes - ambas bibliotecas no parecen estar desapareciendo de la mercadoal menos en los próximos años. En lugar de tomar decisiones basadas en estadísticas y opiniones
de varias personas de Internet, tal vez una mejor opción sea simplemente hablar con los desarrolladores.
Presénteles lo que se espera de la aplicación, de qué plazo disponemos para su entrega y permita un intercambio suelto de opiniones sobre lo que piensan de ambas soluciones antes de tomar la decisión final.
Conclusiones
Las guerras en Internet suelen ser inútiles, o quizá lo sean en todos los casos. Siempre habrá gente que se obstine en afirmar que su opción es mejor sin dar ningún argumento racional que confirme su decisión.
En lugar de cegarnos por opciones concretas, centrémonos en el análisis, intentemos sacar conclusiones adecuadas y utilicémoslas para ajustar o rechazar una solución concreta.
Tal y como indica el título, no pretendo coronar a ninguna biblioteca en particular como la cura para todos los males. En su lugar, se presentan algunas hipótesis y se revelan los puntos fuertes y débiles de ambas bibliotecas. He dado algunos consejos sobre lo que hay que tener en cuenta a la hora de elegir entre ellas para tomar una decisión acertada y no dejarse guiar por modas o personas al azar de internet.
Cada herramienta puede adaptarse bastante bien a las necesidades del proyecto. Ninguna de las dos desaparecerá rápidamente del mercado en los próximos años. Ambas cuentan con potentes comunidades y bastante madurez, lo que nos demuestra que les va bastante bien.
La elección final está en sus manos. No obstante, si tiene alguna duda o simplemente desea comentar su caso con The Codest - no dude en ponerse en contacto con nosotros
Más información:
Por qué debería (probablemente) utilizar Typescript
¿Cómo no matar un proyecto con malas prácticas de codificación?