Det er en stund siden vi har satt en pauseknapp på vår ukentlige gjennomgang av innsiktsfulle tekniske artikler, sannsynligvis på grunn av overbelastning av prosjektarbeid. Men nå er vi i gang igjen, med et oppdrag om å finne, gjennomgå og levere ukentlig innhold av høy verdi for tekniske ledere og programvareutviklere.
Hvorfor gjør vi det?
-
Kunnskapsdeling er avgjørende for å utvikle tekniske ferdigheter, og vi bryr oss.
-
For å hjelpe tekniske ledere med å finne ut hvilke løsninger de trenger for å ta evidensbaserte beslutninger i sine programvareprosjekter.
-
Vi har sterk tro på kraften i egenlæring, og vi streber alltid etter å lære nye ting og styrke oss selv, 1% om gangen
-
Det finnes tonnevis av godt teknisk innhold på nettet som fortjener mer oppmerksomhet, og vi er i ferd med å gi anerkjennelse til dem som fortjener det
Å bygge opp en veikart for denne serien har jeg gjennomført en LinkedIn-undersøkelse for å spørre CTO-er og tekniske ledere om deres viktigste utfordringer i et allerede vanskelig nok 2020 og fremover.
Her er hva de sa:
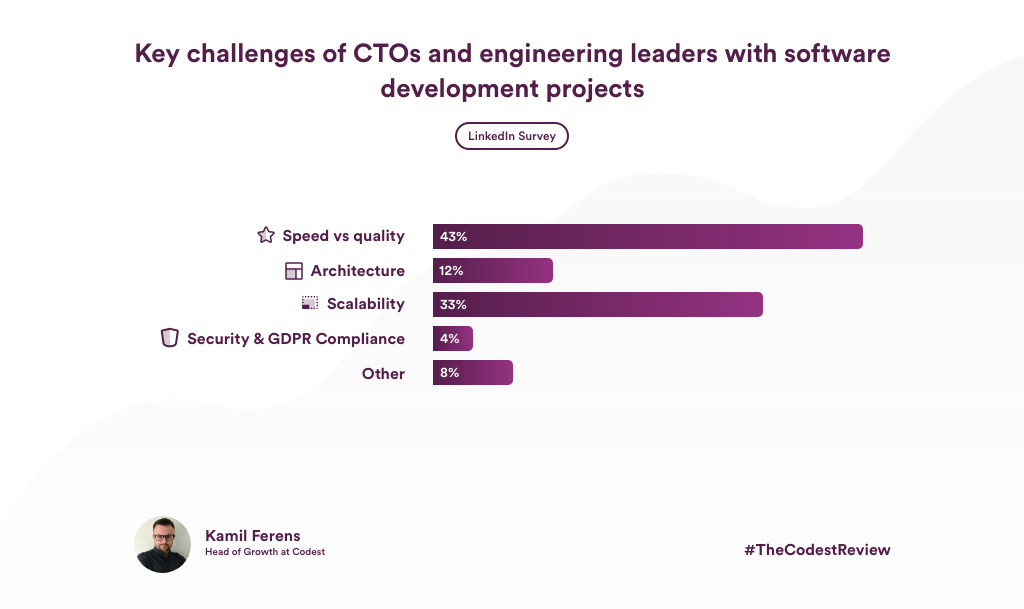
Uten videre, la meg invitere deg til den første episoden av TheCodestReview med gjestebidrag fra vår CTO, Head of Development and Frontend Lead som dekker emnene nedenfor:
"Systemet ditt har en flaskehals. Et eller annet sted!" - når vi kjemper for å forbedre ytelsen til applikasjonen, glemmer vi de viktigste begrensningene i systemet, kanskje de ikke er de mest populære elementene i applikasjonen, men de kan ha en negativ effekt på resten, og skalering hjelper kanskje ikke oss her.
"Overvåking er grunnleggende for skalerbare systemer" - vi kan ikke være blinde i vår virksomhet, og det er bedre for oss å vite om problemet før vi blir informert om det av brukerne eller vår CEO. Overvåking er nøkkelen til pålitelighet.
"Datanivået er vanskeligst å skalere" - Databasen er hjertet i applikasjonen vår, og som alle hjerter er det vanskelig å kutte i den uten å påvirke venesystemet, og derfor er den ofte flaskehalsen. På den annen side, jo lenger vi er på markedjo mer data vi behandler, og jo vanskeligere er det å opprettholde den forventede ytelsen.
I den nevnte artikkelen belyser forfatteren noen spesifikke aspekter ved applikasjonsarkitektur med høy ytelse. I årenes løp har vi lært oss å bruke løsninger som AWS eller Azuremen selv de beste sky beskytter oss ikke mot oss selv. Når vi lager en applikasjon, fokuserer vi ikke på å løse problemer som er fraværende, og forutser dem på forhånd. Derfor støter vi på mange problemer senere når applikasjonen vår vokser. Artikkelforfatteren gir oss mange verdifulle tips om hvor vi skal lete etter optimalisering, hva som er det største problemet og hvordan det påvirker applikasjonen din. Med min mangeårige erfaring i bransjen er jeg helt enig med Ian. Jeg vil også legge til at rådene i artikkelen gjelder for alle applikasjoner vi vedlikeholder. Implementering av disse retningslinjene vil gi fordeler for prosjekt på pålitelighet og forutsigbarhet, noe som er en viktig egenskap for vekst i virksomheten.
- Vanlige prestasjonsmål er ikke strengt tekniske
- Hastigheten på programvareleveransen er målbar, men de brukte indikatorene bør tolkes riktig for at optimaliseringen skal få ønsket effekt
- Den mest effektive team er et godt koordinert og godt sammensveiset team - tekniske ledere bør forstå utviklernes problemer og motivasjoner og vice versa for å oppnå sunne og synergiske effekter.
Juan Pablo Buritica har tatt opp et tema som fortsatt ser ut til å være en nisje. Folk som leder IT-prosjekter tar ofte i bruk noen effektivitetstiltak (for eksempel det grunnleggende burndown-diagrammet i JIRA), men de er fortsatt ikke nært korrelert med leveransene av kode deler for å optimalisere programvareleveranseprosessen basert på dem. Vanligvis handler optimalisering om fordeling av oppgaver og kommunikasjon i teamet, men det er sjelden man sporer rent tekniske indikatorer som forfatteren nevner, f.eks. "tid til sammenslåing". I en tid med GitHub-nettkroker og oppgavehåndteringssystemer som er åpne for integrasjon, blir denne typen tilnærming relativt enkel å bruke - data er lett tilgjengelig, du trenger bare å få tak i dem og behandle dem på riktig måte.
Forfatteren peker med rette på at statistikken han beskriver, raskt kan snu seg mot den utviklingsteamMen dette skjer bare når ledelsen ikke fullt ut forstår detaljene i programmererens arbeid. Derfor er det viktig at prosjektlederen eller PO-en er teknisk kyndig og i stand til å forstå hva som ligger bak de enkelte oppgavene i systemet.
I en pandemitid hvor et stort antall ansatte har gått over til fjernarbeid må vi være enda mer oppmerksomme på sikkerheten til dataene våre. Et godt eksempel er situasjonen Dan nevner, der brukere bruker de samme eller svært like passordene overalt og ikke er klar over faren som er forbundet med det.
Hvis du bruker de samme passordene mange steder, kan det hende at et av nettstedene får "sikkerhetsproblemer", at databasen lekker ut på Internett eller at noen ser deg skrive inn ett passord som ved et uhell åpner alle dørene dine. Etter min mening bør alle nettbaserte tjenester informere deg om faren forbundet med å skrive inn det samme passordet under registreringsprosessen.
Single Sing On (SSO) eller bruk av passordadministratorer som One Identity eller LastPass er svært nyttig for å opprettholde grunnleggende hygiene- og sikkerhetsstandarder på nettet, og beskytter våre ansatte og arbeidsplasser mot sårbarheter og digitale trusler.
Lærer du opp dine ansatte i bevisst passordhåndtering?
Takk for at du leste til slutten, og følg med på neste episode som kommer snart!





