Výkon je jedním z nejdůležitějších aspektů, které je třeba brát v úvahu při vývoji webových aplikací. Analýza způsobu načítání dat z databáze je dobrým výchozím bodem při hledání vylepšení. V tomto článku najdete příklady, jak zlepšit výkon pomocí agregačních funkcí a filtrování dat na úrovni databáze.
Pro začátek několik souvislostí
Tento článek je inspirován skutečným problémem, který jsem kdysi řešil. Jeho řešení mě hodně naučilo a stále ho mám v paměti jako referenci. Myslím, že příklady jsou dobrým zdrojem učení, mohou mnohé objasnit. V tomto článku bych se s vámi rád podělil o několik příkladů použití dotazovacích metod Active Record.
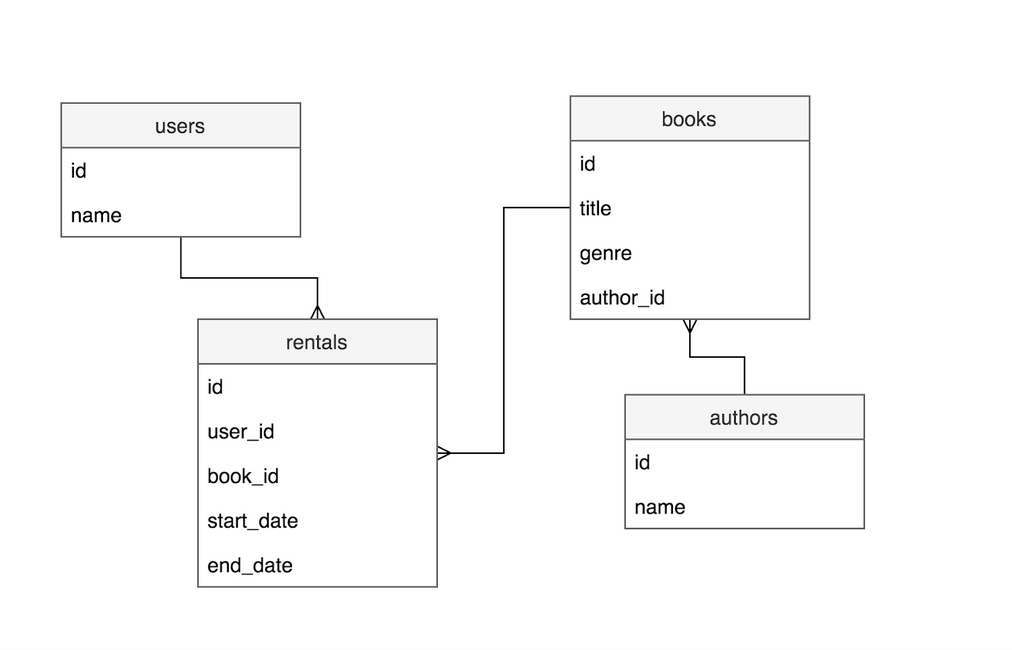
Abych nezaváděl podrobnosti specifické pro danou doménu, použiji pro ilustraci příkladů ukázkovou aplikaci pro knihovnu. Vše je poměrně jednoduché, jak ukazuje následující schéma. Máme čtyři tabulky: autoři, knihy, uživatelé a výpůjčky. Jeden uživatel si může vypůjčit mnoho knih a jednu knihu si může vypůjčit mnoho uživatelů, takže potřebujeme spojovací tabulku pro modelování vztahů mnoho-více. V našem případě je to tabulka pronájmy. V ní také ukládáme některé další informace, kterými jsou data výpůjček a vrácení. Autor může mít ke svému jménu přiřazeno mnoho knih. Kniha má také atribut definující její žánr.
Statistiky čtení uživatelů
Úkolem bylo připravit statistiku pro jednoho uživatele, abychom mohli zjistit, kolik knih z jednotlivých žánrů si vypůjčil. Nejdříve mě napadlo načíst všechny knihy, které si uživatel vypůjčil, seskupit je podle žánru a pak provést mapování, takže každý žánr bude mít místo seznamu přiřazený počet knih. Zde je to, co jsem vymyslel:
Tento přístup sice funguje a vypadá čistě, ale nevyužívá všechny možnosti, které nabízejí metody dotazování Active Record. Díky nim jsme schopni filtrovat a agregovat data na úrovni databáze, aniž bychom museli používat hrubý jazyk SQL přímo v našem kód. Provoz na úrovni db také zvyšuje naši efektivitu.
Ve výše uvedeném příkladu můžeme použít metodu group namísto metody group v jazyce Ruby.metodou. Bude použita skupina GROUPklauzuli BY do dotazu tSQL. Dále lze metodu mapování a velikost nahradit agregační funkcí pro počítání. Nakonec nám zůstane dotaz, který vypadá takto:
Book.joins(:rentals).where(rentals: { user: user }).group(:genre).count(:books)
Vypadá to ještě jednodušeji!
Další užitečné příklady
Níže najdete několik dalších způsobů použití dotazovacích metod, které považuji za užitečné.
Pozvánka pro neaktivní uživatele
ÚKOL: Vyfiltrujte uživatele, kteří si nikdy nepůjčili knihu nebo tak učinili před více než rokem.
Mohli bychom získat všechny uživatele včetně přidružených pronájmů a poté je filtrovat pomocí metody select.
User.includes(:rentals).select do |user|
user.rentals.empty? || user.rentals.none? { |pronájem| pronájem.start_date >= Date.today - 1.year }
end
Samozřejmě však není nutné přebírat všechno. Pomocí metod dotazování je můžeme vyfiltrovat na úrovni db. Nejprve vybereme uživatele, kteří si v posledním roce vypůjčili nějaké knihy, a ty pak z konečného výběru vyloučíme.
Při používání left_joins (a vnějších spojů obecně) je důležité pamatovat na jednu věc. Pokud jsou v levé tabulce (zde: autoři) záznamy, které nemají odpovídající záznamy v pravé tabulce (zde: knihy), pak budou ve výsledku sloupce pravé tabulky vyplněny nulovými hodnotami.
Protože v systému potřebujeme také autory s jednou přiřazenou knihou, je třeba provést ještě několik dalších operací. Budeme muset provést seskupování, počítání a přidání podmínky. Zde je návod, jak to všechno dát dohromady:
Podmínka se objevuje až za agregační funkcí, takže ji musíme zadat pomocí klauzule HAVING namísto klauzule WHERE.
Při přemýšlení o výkonu aplikace stojí za to zkontrolovat metody dotazování Active Record. Mohou zjednodušit váš kód a zrychlit jeho práci. Doufám, že vám sdílené příklady pomohou při zkoumání možností, které dotazovací metody nabízejí.